在2019年,从Linux内核5.1开始,引入了io_uring这样的异步框架,io_uring的设计非常精巧,经过验证,其性能极其强悍,在文件读写的领域已经证明了其巨大的价值。很多数据库系统的底层已经引入并采用了io_uring这个组件。其文件读写性能远远超过了原来Linux中的AIO异步接口。下图是io_uring的4k顺序读和写与AIO顺序读写的性能差异。
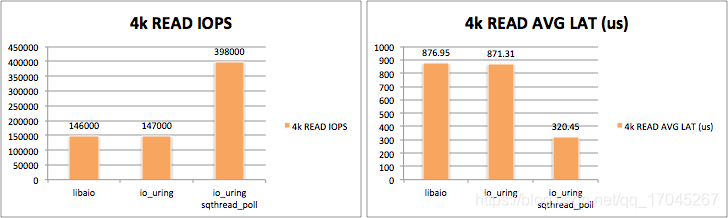
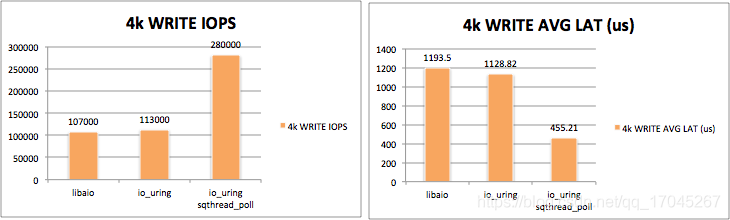
不过很长一段时间,io_uring一直被认为只是在文件读写这种不需要缓存的场景下有非常优秀的表现。而且,在相当长的一段时间内,还没有公开发布真正用io_uring实现,并且能够大幅领先目前以select/epoll接口为基础基于reactor模式的网络I/O框架。从经验上判断,通过内核态环形缓存的方式去发送和接收I/O事件的方式理论上肯定是要比传统的不断调用epoll系统调用的性能要优秀。经过反复验证,觉得目前io_uring 网络I/O的瓶颈应该还是出在并发性上面。大多数时候,一个io_uring实例只会占用一个CPU内,要加速带有缓存的I/O,那么多线程肯定是必选项,因为I/O访问中有大量的时间是用在等待缓存的读写和拷贝,以及网络传输延迟上面了。这些系统等待时间肯定应该用其他的线程/进程进行填补。
io_uring对于I/O类型分为两种,分别叫bounded I/O和unbounded I/O这两种类型。其实,bounded I/O就是指的读写时间是有一个固定的时间范围的输入和输出方式,比如文件读写和块设备的输入输出。unbounded I/O指的是像网络socket通信这样的不确定性比较大的输入和输出方式。网络socket通信每次的读写完成的时间不确定,甚至最后无法完成。
By default, io_uring limits the unbounded workers created to the maximum processor count set by RLIMIT_NPROC and the bounded workers is a function of the SQ ring size and the number of CPUs in the system.
io_uring的文档中提到,如果是unbounded情况下,最大的I/O并发数由RLIMIT_NPROC这个系统参数设定。而在bounded这种情况下的并发数量是由SQ ring的大小和CPU数量决定的。
对于我们比较关心的网络I/O的情况,具体是怎样的呢?事实上,socket I/O默认是采用的Non-block方式,也就是传统的Epoll这样的模式处理,在这种情况下,io_uring本质上还是进行的epoll操作。为了能够在网络I/O中采用异步多线程模式,我们必须强制网络请求通过block的方式,也就是阻塞模式进行访问。在创建和提交SQ的时候,可以加入IOSQE_ASYNC参数,这样就会通过线程池处理每个请求了。这样的I/O性能实际测试下来还是比epoll的模式稍差一些的。同时和普通模式下的io_uring的网络I/O相比,CPU的占用率也没有显著的改善。因此这种模式在网络I/O应用显得比较鸡肋。
对于epoll模式,单纯的提高并发数量并不能有效地提升IO性能,尤其像io_uring这样已经将系统调用频次降低到了相当少的程度。在我自己的虚拟机环境种,通过采用wrk的http压测,两个线程,两个io_uring实例的情况下,就几乎已经达到压测的极限性能。再增加线程和实例反而由于线程调度的消耗,最高性能还会下降。不过,经过验证,适当地增加并发运行的io_uring实例可以大大提升整体性能。在echo server压力测试的场景种,几乎能够达到目前最快的基于epoll框架的两倍的性能,而在http server的压力测试下,经过调试的框架可以至少领先基于epoll的框架20%以上,同时平均响应延迟以及延迟时间的标准差都要好于目前各类Web I/O框架。
除了并行,还有两种可以大大提高基于io_uring网络框架性能的方式,其中一个是用io_ring提供的内核态用户态共享的buffer机制。可以通过IORING_OP_PROVIDE_BUFFERS这个操作,分配内核+用户态共享的缓存,避免了socket数据读取时,内核空间到用户空间的拷贝所造成的系统开销。另外一个提高性能的方式是可以在创建io_uring的时候加入IORING_SETUP_SQPOLL参数,这样io_uring就会开启自动SQ提交模式,我们可以不需要通过每次调用内核的enter方法来提交SQ,大大加快了IO事件的处理速度。经过测试,大约能获得10%-20%的性能提升。不过这种自动提交模式也有一定的副作用,那就是会大大增加CPU的占用率,在响应网络I/O请求时,一个io_uring实例会将一个CPU核心的占用率拉到100%,而且在有I/O访问的整个时间段内,会持续高CPU占用率,同时CPU占用率和访问压力无关。总之,尽管IORING_SETUP_SQPOLL这个参数可以提高性能,但是需要慎用。只有在追求极限性能得时候可以尝试。
后面就不做过多得介绍了,我们直接上对比测试结果。目前这个框架正在开发和完善中。项目主要语言是Golang写,所以几个对标的网络框架也都是Golang语言的。主要比较的框架有gnet,原生net库,以及fasthttp。
Echo 压力测试结果
用于Echo压力测试的工具是rust echo bench。
测试环境:
主机:
CPU:Intel Core i5 12400F 6 core 12 thread
Memory: DDR4 32GB
OS:Windows 11
测试虚拟机:
VMware® Workstation 16 Pro
Processors: 8P ; Memory 16GB; 开启硬件虚拟化支持Intel VT-x
OS:Ubuntu 22.04.1 LTS, Kernel:5.19.3
echo压力测试最终测试结果统计

echo测试结论:
我们看到,在简单的echo压力测试种,采用了io_uring技术的UringNet展现出了异常强悍的基础性能,在UringNet+SQPoll开启的情况下能够达到现有高性能框架的150%~200%性能。尤其是在500连接数和512bytes测试中领先了一倍。总体来说,在对传统epoll模式框架下的web I/O形成了碾压性的性能优势。
各测试项结果
测试1:连接数-500,收发包大小-512 bytes

测试2:连接数-1000,收发包大小-512 bytes

测试3:连接数-1000,收发包大小-1024 bytes

HTTP压力测试
HTTP压力测试,采用了比较常用的wrk压测工具。压测环境为:
主机:
CPU:Intel Core i5 12400F 6 core 12 thread
Memory: DDR4 32GB
OS:Windows 11
被测程序虚拟机:
VMware® Workstation 16 Pro
Processors: 8P ; Memory 16GB; 开启硬件虚拟化支持Intel VT-x
OS:Ubuntu 22.04.1 LTS, Kernel:5.19.3
wrk运行的虚拟机:
VMware® Workstation 16 Pro
Processors: 4P ; Memory 8GB; 开启硬件虚拟化支持Intel VT-x
OS:Ubuntu 20.04.5 LTS, Kernel:5.15.0
HTTP压力测试结果统计

HTTP测试结论:
我们看到,在简单的HTTP压力测试中,和其他的框架相比,在http测试中UringNet仍然保持者比较明显的优势,尤其是在连接数在200的情况下,由于测试是在同一台主机上运行,测试程序和被测试程序都运行在同一台宿主机的桌面虚拟机中,因此在多线程,高并发下实际上对被测试程序的结果有些影响。另外由于缓存部分优化没有现有的框架这么完善,因此优势看上去和没有echo测试那么巨大。
另外,在所有的测试对比中,UringNet的响应能力明显占优,在响应延迟上和响应时间和每秒响应数量的正态偏离指标上也有不少亮点。这说明以io_uring为基础的网络I/O框架也有比较良好的稳定性和一致性。
各测试项结果
测试1:连接数-200,线程数-4
FastHttp:

Gnet:

UringNet:

测试2:连接数-200,线程数-2
FastHttp:

Gnet:

UringNet:

测试3:连接数-400,线程数-4
FastHttp:

Gnet:

UringNet:

测试4:连接数-400,线程数-2
FastHttp:
Gnet:

UringNet:

测试5:连接数-600,线程数-4
FastHttp:

Gnet:

UringNet:

测试6:连接数-600,线程数-2
FastHttp:

Gnet:

UringNet:



文章评论