Uber是全球最大的打车软件公司,而且正在发展为最大的车辆共享软件公司。对于Uber这样的公司来说,对巨量的实时流数据的处理的能力是至关重要的,其实时流数据的处理能力,效率和质量直接关系到公司核心业务的服务质量和用户的满意度。不知道滴滴在技术上是不是可以和Uber一拼,这里没有可能有挑战的意味:)。这篇文章通过研究Uber程序员在Devoxx,WSO2Con, DataWorks Summit等会议上的分享来分析其实时流数据分析的体系架构。也作为今年技术研究的一个方向做一个分析。
![]()
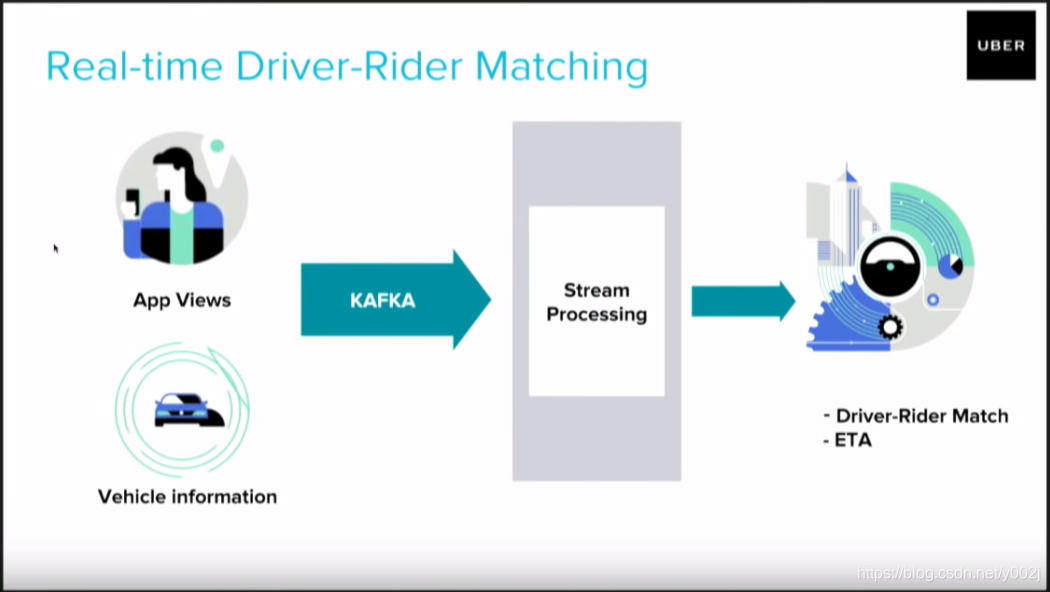
可以看到其实时流系统是采用的Kafka,其实Kafka最早是Linkedin开发的一个消息传输工具,但是其性能还是非常卓越的,在很多公司的系统中已经被作为实时流系统的提供程序。
![]()
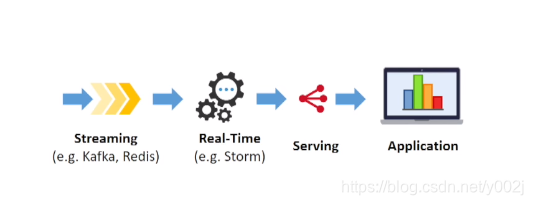
上图是实时流系统的简化结构,可以看到streaming这一块,就是实时流提供程序。Uber采用了Kafka,那他们处理的数据规模大概达到了什么级别呢:

![]()
在介绍中他们提到了一个数据,每秒钟达到千万级的消息量。这个数子确实非常惊人。
![]()
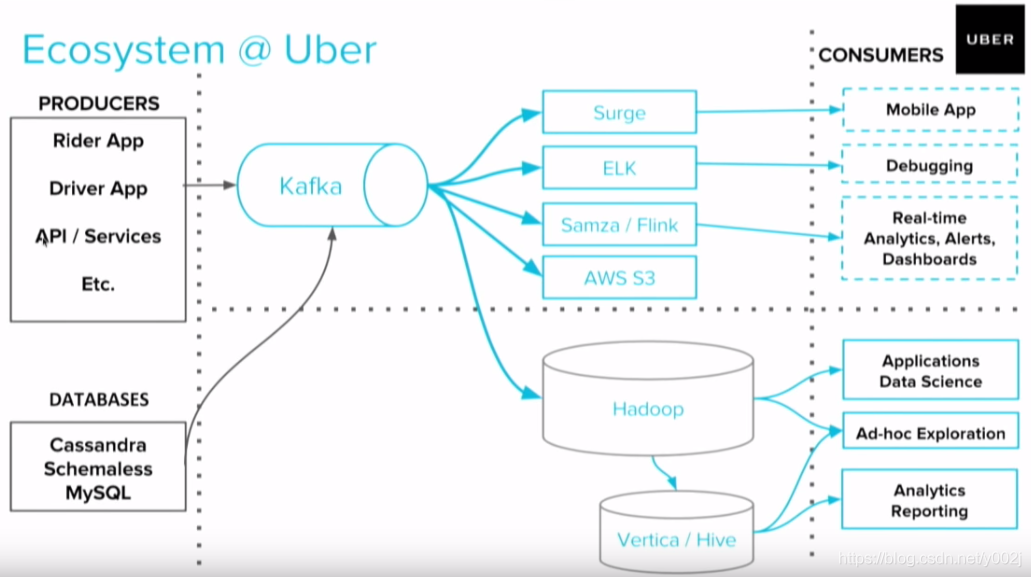
这个是一个Uber系统的简单结构示意,可以看出来,Kafka其实是作为了其整个架构体系的数据总线在使用。司机和打车的人的实时数据不断地进入Kafka的消息平台,同时聚合了数据库的数据(Cassandra,MySql - 账户信息,元数据等)一提供给用户个性化的服务和实时的人车匹配算法。其实打车时的业务场景是很容易想象的,这个时候乘客的位置,乘客周围的环境等信息是作为实时数据输入系统的;同时当地的所有车辆的位置,司机状态,车辆状态等信息也必须是保持实时传输。系统必须要及时知道双方的信息,同时还要结合数据库中车辆型号,司机个人信息,以及乘客个人信息和特点做出车辆匹配和调度的决定。整个过程必须准确和快速。
有了实时数据流的组件,那么需要提供一个流数据的引擎,对其进行实时处理,那么才能发挥流数据的价值。Uber采用的流数据处理程序是Samza,这个引擎其实本身就是和Kafka配套开发的,天生就和Kafka能够紧密绑定。
![]()
可以看到蓝色的部分就是processor,对应的就是Samza在起作用。
![]()
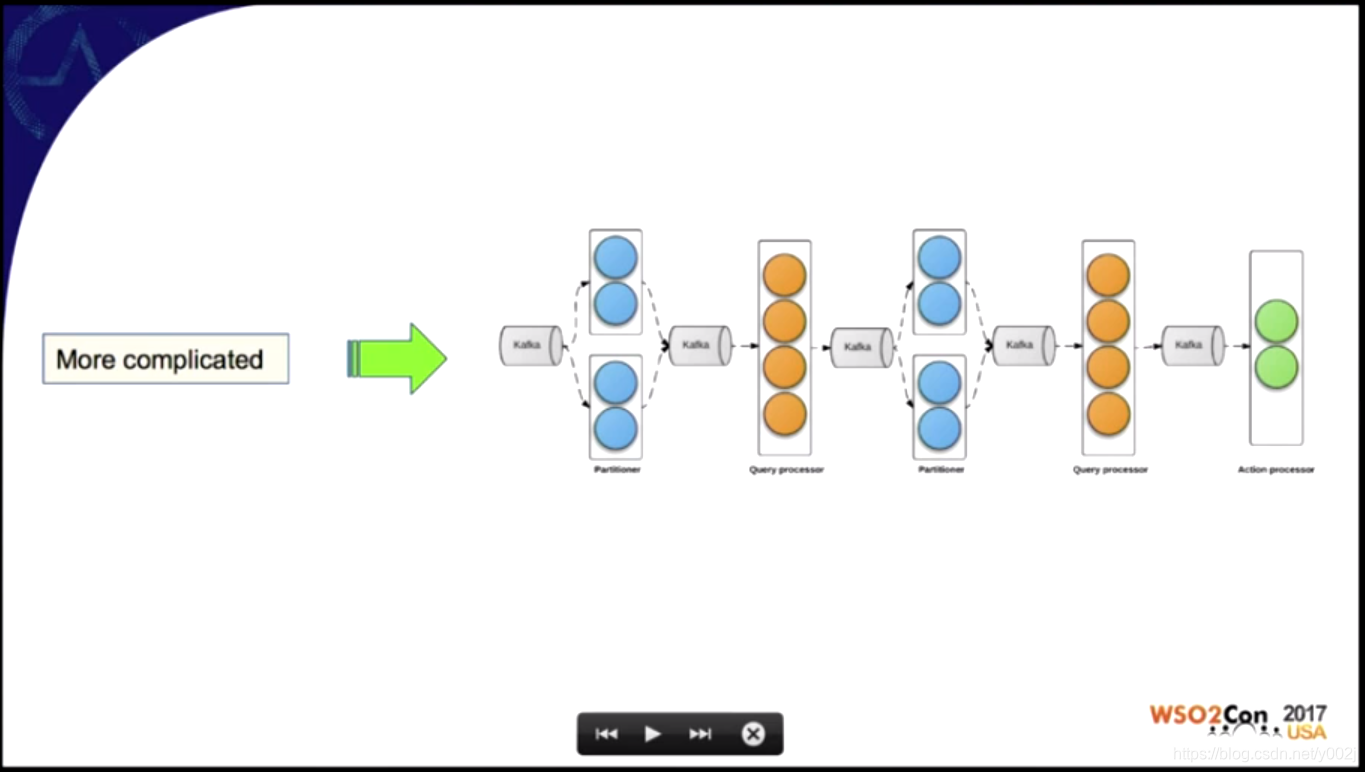
对于实时流处理的概念其实还不是一下就能够说清楚,不过我觉得Kafka和Samza的关系可以用下面这个图来表示,Samza Job中对Kafka的中的实时消息进行过滤,加工,整理,如果有必要,继续传递到下一级去处理。
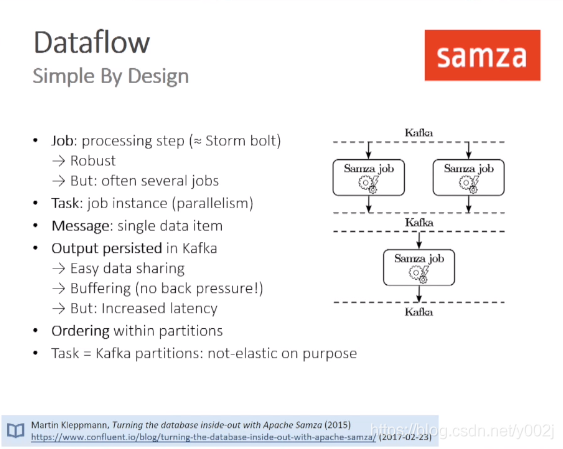
![]()
最后要介绍的就是CEP Engine了,Uber使用的是Siddhi。CEP的全称是叫复杂事件处理引擎,这个是干什么用的呢?其实这个工具才是真正处理和使用流数据的软件,这个工具截取一个窗口(一个时间段)的流数据,然后做聚合,查询,分析等等。![]()
在Uber的系统中,它起的作用是这样的,通过执行plan runtime来分析并输出处理结果。
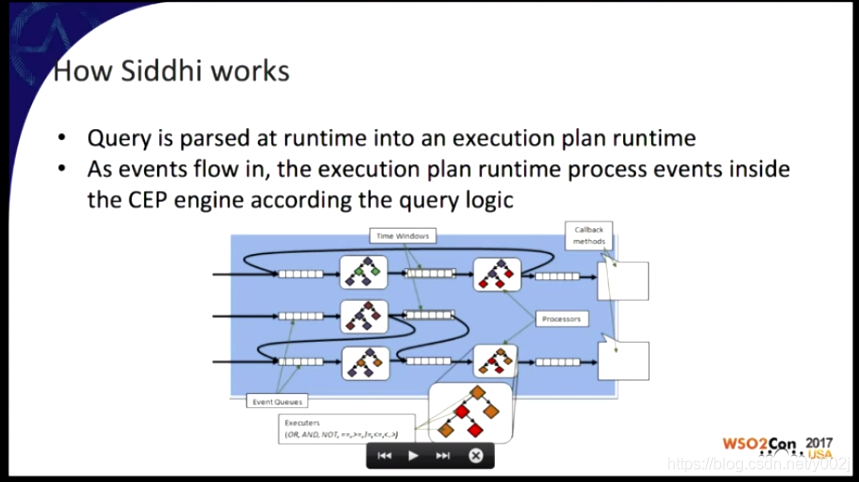
![]()
Siddhi使用类SQL语言SiddhiQL进行数据炒作,举个例子,这个是查询10分钟内同一个IP地址用不同账号登录10次以上的可疑IP。
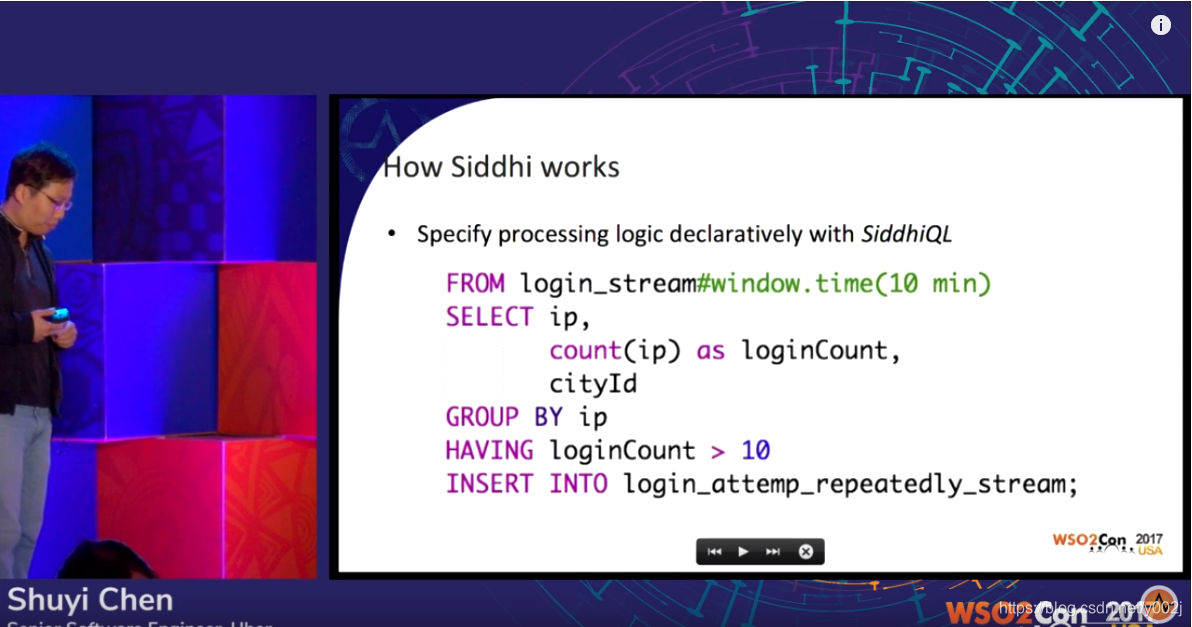
![]()
OK,时候不早了,这篇文章先写到这里。后面再继续补充吧.....


文章评论